Có hai cách phổ biến để nhóm các thuật toán học máy. Một dựa trên phong cách học tập và một dựa trên chức năng (mỗi thuật toán).
Trên trang này:
- 1. Phân nhóm dựa trên các phương pháp học tập
- Học tập có giám sát
- Phân loại
- Hồi quy
- Phân cụm
- Liên kết
- Thuật toán hồi quy
- Thuật toán phân loại
- Thuật toán dựa trên phiên bản
- Thuật toán điều chỉnh
- Thuật toán Bayes
- Thuật toán phân cụm
- Thuật toán mạng nơron nhân tạo
- Thuật toán giảm thứ nguyên
- Thuật toán tích hợp
- Hồi quy tuyến tính
- Hồi quy logistic
- Hồi quy từng bước
- Bộ phân loại tuyến tính
- Máy vectơ hỗ trợ (svm)
- svm hạt nhân
- Phân loại dựa trên biểu diễn thưa thớt (src)
- k-láng giềng gần nhất (knn)
- Học lượng tử hóa vectơ (lvq)
- Hồi quy Ridge
- Toán tử lựa chọn và co ngót tuyệt đối ít nhất (Lasso)
- Hồi quy góc thấp nhất (lars)
- Naive Bayes
- Naive Bayes của Gaussian
- k-means clustering
- k-medians
- Tối đa hóa kỳ vọng (em)
- Perceptron
- hồi quy softmax
- Perceptron nhiều lớp
- Cộng đồng ngược
- Phân tích thành phần chính (pca)
- Phân tích phân biệt tuyến tính (lda)
- tăng cường
- adaboost
- Rừng Ngẫu nhiên
-
Tham quan các thuật toán học máy
Xem các thuật toán học máy hiện đại
ul>
1. Phân nhóm dựa trên phương pháp học tập
Tùy thuộc vào phương pháp học, các thuật toán học máy thường được chia thành 4 nhóm: học có giám sát, học không giám sát, học bán giám sát và học tăng cường. Trong trường hợp không có phương pháp học bán giám sát hoặc học tăng cường, có một số phương pháp phân nhóm.
Học tập có giám sát
Học tập có giám sát là một thuật toán dự đoán đầu ra (kết quả) của dữ liệu mới (đầu vào mới) dựa trên các cặp (đầu vào, kết quả) đã biết trước đó. Cặp dữ liệu này còn được gọi là (dữ liệu, nhãn), tức là (dữ liệu, nhãn). Học có giám sát là nhóm thuật toán học máy phổ biến nhất.
Trong toán học, học có giám sát là khi chúng tôi xuất ra một tập hợp các biến đầu vào ( mathcal {x} = { mathbf {x} _1, mathbf {x} _2, dot, mathbf {x} _n } ) và một bộ nhãn tương ứng ( mathcal {y} = { mathbf {y} _1, mathbf {y} _2, dot, mathbf {y} _n } ), trong đó ( mathbf {x} _i, mathbf {y} _i ) là một vectơ. Cặp dữ liệu đã biết (( mathbf {x} _i, mathbf {y} _i) in mathcal {x} times mathcal {y} ) được gọi là tập dữ liệu huấn luyện. ). Từ tập dữ liệu đào tạo này, chúng ta cần tạo một hàm ánh xạ từng phần tử trong tập hợp ( mathcal {x} ) với phần tử tương ứng (gần đúng) trong tập hợp ( mathcal {y} ):
[ mathbf {y} _i khoảng f ( mathbf {x} _i), ~~ forall i = 1, 2, dot, n ] Mục đích là để tính gần đúng hàm (f ) sao cho Khi chúng ta có một dữ liệu mới ( mathbf {x} ), chúng ta có thể tính nhãn tương ứng của nó ( mathbf {y} = f ( mathbf {x}) ).
Ví dụ 1: Trong nhận dạng chữ viết tay, chúng tôi có hình ảnh của hàng nghìn ví dụ về mỗi chữ số được viết bởi nhiều người khác nhau. Chúng tôi đưa những hình ảnh này vào thuật toán và cho nó biết mỗi hình ảnh tương ứng với số nào. Sau khi thuật toán tạo ra một mô hình, một hàm có đầu vào là hình ảnh và đầu ra của nó là một số, khi mô hình nhận được một hình ảnh mới chưa từng thấy , nó sẽ dự đoán hình ảnh đó chứa số nào. p>
Ví dụ này rất giống với cách mọi người học khi còn nhỏ. Chúng tôi đưa cho một đứa trẻ bảng chữ cái và nói với chúng đó là chữ cái a và đây là chữ cái b. Sau một vài buổi học, trẻ có thể nhận ra đâu là chữ cái và đâu là chữ b trong một cuốn sách mà chúng chưa từng xem trước đây.
Xem Thêm : Vô cảm là gì? Nguyên nhân, biểu hiện và sự ảnh hưởng
Ví dụ 2: Các thuật toán phát hiện khuôn mặt trong hình ảnh đã được phát triển trong một thời gian dài. Lúc đầu, Facebook sử dụng thuật toán này để xác định khuôn mặt trong ảnh và yêu cầu người dùng gắn thẻ bạn bè – tức là gán một thẻ cho mỗi khuôn mặt. Càng nhiều cặp dữ liệu (khuôn mặt, tên), độ chính xác của việc dán nhãn tự động tiếp theo càng cao.
Ví dụ 3: Bản thân thuật toán phát hiện khuôn mặt trong hình ảnh là một thuật toán học tập có giám sát, được đào tạo trên hàng nghìn cặp (hình ảnh, khuôn mặt) và (ảnh, không phải khuôn mặt) được bao gồm. Lưu ý rằng dữ liệu này chỉ phân biệt giữa khuôn mặt của con người và không phải của con người, không phải khuôn mặt của những người khác nhau.
Các thuật toán học tập có giám sát được chia nhỏ thành hai loại lớn:
Danh mục
Nếu các nhãn của dữ liệu đầu vào được chia thành một số nhóm hữu hạn, nó được gọi là bài toán phân loại. Ví dụ: gmail xác định xem một email có phải là thư rác hay không; các văn phòng tín dụng xác định xem khách hàng có thể trả nợ của họ hay không. Ba ví dụ trên thuộc loại này.
Hồi quy
(Bản dịch tiếng Việt trả lại, tôi không thích bản dịch này vì tôi không hiểu nghĩa của nó)
Nếu thẻ không được nhóm lại mà là một giá trị thực tế cụ thể. Ví dụ: một ngôi nhà lớn (x ~ text {m} ^ 2 ) với (y ) phòng ngủ và cách xa trung tâm thành phố (z ~ text {km} ) sẽ có giá bao nhiêu?
Gần đây Microsoft có một ứng dụng dự đoán giới tính và độ tuổi dựa trên khuôn mặt. Phần dự đoán giới tính có thể được coi là một thuật toán phân loại và phần dự đoán độ tuổi có thể được coi là một thuật toán hồi quy . Lưu ý rằng phần dự đoán tuổi cũng có thể được coi là danh mục , nếu chúng tôi coi tuổi là một số nguyên dương không lớn hơn 150, chúng tôi sẽ có 150 danh mục riêng biệt.
Học tập không giám sát
Trong thuật toán này, chúng tôi không biết kết quả hoặc nhãn, chỉ biết dữ liệu đầu vào. Các thuật toán học không giám sát dựa vào cấu trúc của dữ liệu để thực hiện một công việc nhất định, chẳng hạn như phân cụm hoặc giảm kích thước của dữ liệu để tạo điều kiện cho việc lưu trữ và tính toán.
Trong toán học, học không giám sát có nghĩa là chúng ta chỉ có đầu vào ( mathcal {x} ) mà không biết nhãn ( mathcal {y} ) tương ứng.
Các thuật toán này được gọi là học không giám sát vì không giống như học có giám sát, chúng tôi không biết câu trả lời chính xác cho từng đầu vào. Giống như khi chúng ta học, không có giáo viên nào cho chúng ta biết đó là chữ a hay chữ b. Các cụm không được giám sát được đặt tên theo nghĩa này.
Các vấn đề học tập không được giám sát được chia thành hai loại:
Phân cụm
Xem Thêm : Concept là gì? Một số mẫu concept đẹp bạn nên tham khảo
Bài toán nhóm tất cả dữ liệu ( mathcal {x} ) thành các nhóm con dựa trên mối tương quan của dữ liệu trong mỗi nhóm. Ví dụ: phân khúc khách hàng dựa trên hành vi mua hàng. Nó giống như việc đưa cho trẻ nhiều câu đố có hình dạng và màu sắc khác nhau, chẳng hạn như hình tam giác, hình vuông, hình tròn xanh và đỏ, và yêu cầu trẻ nhóm chúng lại. Ngay cả khi trẻ không biết câu đố nào tương ứng với hình dạng hoặc màu sắc nào, trẻ vẫn có thể sắp xếp các câu đố theo màu sắc hoặc hình dạng.
Lenovo
là vấn đề khi chúng tôi muốn khám phá các quy tắc dựa trên nhiều dữ liệu nhất định. Ví dụ: khách hàng nam mua quần áo có xu hướng mua đồng hồ hoặc thắt lưng nhiều hơn; khán giả phim Người nhện có xu hướng xem phim Người dơi nhiều hơn, tạo hệ thống giới thiệu khách hàng dựa trên điều này để tăng nhu cầu mua sắm.
Học tập bán giám sát
Vấn đề mà chúng tôi có nhiều dữ liệu ( mathcal {x} ) nhưng chỉ một phần dữ liệu được gắn nhãn được gọi là học bán giám sát. Các câu hỏi trong nhóm này nằm giữa hai nhóm trên.
Một ví dụ điển hình về nhóm này là khi chỉ một phần của hình ảnh hoặc văn bản được gắn thẻ (chẳng hạn như hình ảnh về người, động vật hoặc văn bản khoa học hoặc chính trị), trong khi hầu hết các hình ảnh / văn bản không được gắn thẻ khác được thu thập từ internet. Trên thực tế, nhiều vấn đề về học máy thuộc loại này vì việc thu thập dữ liệu được gắn nhãn rất tốn thời gian và tốn kém. Nhiều loại dữ liệu thậm chí yêu cầu các chuyên gia phải dán nhãn (chẳng hạn như hình ảnh y tế). Thay vào đó, dữ liệu không được gắn nhãn có thể được lấy từ Internet với chi phí thấp.
Học tập củng cố
Học tập củng cố là vấn đề giúp hệ thống tự động xác định hành vi dựa trên tình huống để đạt được lợi ích lớn nhất (tối đa hóa hiệu suất). Hiện tại, việc học củng cố phần lớn được áp dụng cho lý thuyết trò chơi, nơi mà thuật toán cần xác định bước tiếp theo để đạt điểm cao nhất.
Ví dụ 1: alphago gần đây đã trở nên nổi tiếng khi chơi cờ vây với con người. Cờ vây được coi là cực kỳ phức tạp, tổng số nước đi vào khoảng (10 ^ {761} ), trong khi cờ vua là (10 ^ {120} ), tổng số nguyên tử trong toàn vũ trụ là khoảng (10 ^ {80} )! ! Vì vậy, thuật toán phải chọn ra một nước đi tối ưu từ hàng tỷ lựa chọn, chắc chắn không phải là thuật toán giống như ibm deep blue (ibm deep blue đánh bại con người ở cờ vua 20 năm trước). Về cơ bản, alphago bao gồm các thuật toán thuộc về học có giám sát và học tăng cường. Trong quá trình học có giám sát, dữ liệu về con người chơi cờ vua được đưa vào quá trình huấn luyện. Tuy nhiên, mục tiêu cuối cùng của alphago không phải là chơi như một con người, mà là để đánh bại nó. Vì vậy, sau khi tìm hiểu trò chơi của con người, alphago đã chơi với hàng triệu trò chơi để tìm ra các bước di chuyển mới, tối ưu hơn. Các thuật toán trong kiểu tự chơi này được phân loại là học củng cố. (Xem thêm trong alphago của google deepmind: nó hoạt động như thế nào).
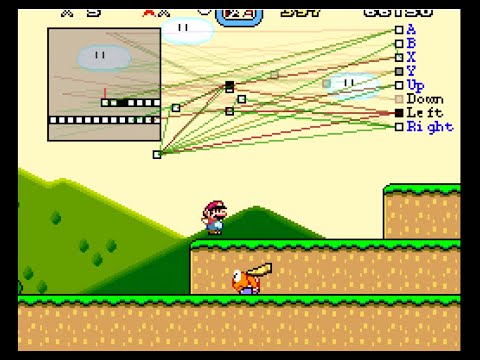
Ví dụ 2: Đào tạo máy tính mario. Đây là một chương trình thú vị hướng dẫn máy tính cách chơi trò chơi Mario. Trò chơi này đơn giản hơn cờ vây, vì người chơi chỉ phải nhấn một vài nút cùng một lúc (di chuyển, nhảy, bắn) hoặc không có nút nào cả. Đồng thời, phản ứng của máy cũng đơn giản hơn, lặp lại từng lần chơi (các chướng ngại vật cố định ở các vị trí cố định xuất hiện vào những thời điểm nhất định). Đầu vào cho thuật toán là một biểu đồ màn hình của thời gian hiện tại và nhiệm vụ của thuật toán là nhập, tổ hợp phím nào sẽ được nhấn. Việc đào tạo này dựa trên điểm số thời gian bạn lái xe trong trò chơi, càng đi xa càng nhanh, phần thưởng càng cao (phần thưởng này không phải là điểm trò chơi mà là điểm trò chơi. Do lập trình viên tạo ra). Thông qua đào tạo, thuật toán sẽ tìm ra cách tối ưu để tăng tối đa số điểm trên, nhằm đạt được mục đích cuối cùng là cứu công chúa.
2. Phân nhóm dựa trên chức năng
Có một cách phân nhóm thứ hai dựa trên các hàm thuật toán. Trong phần này, tôi chỉ muốn liệt kê các thuật toán. Thông tin chi tiết sẽ được đề cập trong các bài viết khác trên blog này. Khi tôi viết, tôi có thể thêm hoặc bớt một số thuật toán.
Thuật toán hồi quy
Thuật toán phân loại
Thuật toán dựa trên phiên bản
Thuật toán điều chỉnh
Thuật toán Bayes
Thuật toán phân cụm
Thuật toán mạng nơ-ron nhân tạo
Thuật toán giảm thứ nguyên
Thuật toán tích hợp
Có nhiều thuật toán khác.
3. Tài liệu tham khảo
- Học tập có giám sát
Nguồn: https://xettuyentrungcap.edu.vn
Danh mục: Hỏi Đáp



